
Smaller DevOps teams are winning with agentic automation
Why Your DevOps Team is Burning Out (And What Actually Helps)

Human + AI is the way forward in tech

Disclosure: This post contains a paid partnership with Nudgebee. I tested the product myself before writing about it.
As a DevOps engineer, one thing I hate more than anything else is waking up at 5 AM for an alert, only to find out it was a false alarm.
Last month, I got paged at 5 AM. Production alert. I jumped out of bed, opened my laptop, started digging through logs across three tools, and pinged two people on Slack.
Turned out to be a false alert. A simple threshold misconfiguration that any pattern-to-action rule could have caught and closed automatically.
I went back to sleep angry. Because I knew that the alert should never have reached my phone.
That moment stuck with me. Because it is not rare. It happens to DevOps and SRE engineers every week across thousands of teams.
And it is a symptom of a much bigger problem.
The Work Grew. The Team Did Not.
Five years ago, companies had separate teams. Cloud team. DevOps team. SRE team. Clear boundaries, clear ownership.
Today, most organisations have collapsed all of that into two or three people. Same work. Smaller team. And the expectations have not gone down; they have gone up.
What happens when you shrink the team but not the workload? Alert fatigue. Engineers start tuning out notifications because there are too many of them. And then the one alert that actually matters gets buried in the noise. That is how a 30-minute fix turns into a 3 AM incident that eats half your next day.
The problem is not the people. The problem is that the system has not kept up with how the work actually runs now.
Three Things Quietly Killing Your Team
Every incident is a detective story before it is a fix.
When something breaks, your first hour is not fixing it. It is figuring out where even to look.
You open Prometheus, then Datadog, check the last deployment, then ping whoever last touched that service. All before you have a single lead.
MTTR is high, not because engineers are slow. It is because the first hour of every incident is just correlation work that should not need a human.
Cloud costs bleed out in plain sight
That test environment that was supposed to run for a week? Six months later, still running. That node you overprovisioned for a load test that finished months ago? Still there, still billing.
Over-provisioning quietly eats 30 to 60% of cloud budgets in most teams I have seen. It’s not like nobody cares about optimising cost, because continuously optimising this is a full-time job, and everyone is already doing three other full-time jobs( Managing infra, deployments, and monitoring )
The important but boring work never gets done properly
Certificate renewals.
CVE scanning.
RCA documentation.
Kubernetes upgrade compatibility checks.
Jira tickets for every incident.
All of it matters. None of it is why anyone got into DevOps.
And when these pile up, experienced engineers start looking for roles where they can do more interesting work.
I personally hated writing RCAs. Not because they are not useful. They are. But sitting down to document an incident properly after two hours of debugging at 3 AM is punishment.
Your brain is fried, you just want to sleep, and you still have to write a structured timeline of what happened.
That is the kind of work AI should be doing, not you.
Role of AI in modern day Devops/SRE workflow
See, I Do Not Buy the “Let AI Do Everything” Pitch.
I have used AI deeply in my workflow for three years. AI is genuinely useful for dedicated tasks with limited context and a clear direction.
Give it a specific job, constrain what it can touch, and tell it exactly what good looks like. It will do that job well and consistently.
Just do not give it too much freedom or ask it to make judgment calls on your behalf. AI will make mistakes. Sometimes very confidently.
But AI does play a big role here, and I will be honest about that too.
AI has made me genuinely more productive. Not 10x like the LinkedIn posts claim. But 2 to 3x, consistently, when I use it the right way.
That is the whole game. Use AI where it adds real value, and stay in the loop for everything that needs judgment
I recently spoke with the engineering team at Nudgebee, a startup building AI assistants for DevOps and SRE workflows.
Their founders are tackling exactly the problems I just described, with a focus on eliminating toil from day-to-day DevOps work.
They gave me early access to try it out. I played with it for a few days, and it looked genuinely promising.
It did not feel like another “let AI do everything” pitch. It felt more like a platform that quietly handles the work DevOps and SRE engineers find least enjoyable but cannot ignore.
The compliance checks, the cost reviews, the incident documentation, and the CVE scans. The work that matters but drains you.
Taking a look at Nudgebee
Nudgebee acts as an always-on DevOps/SRE assistant that detects security issues, rightsizes your infrastructure, tracks compliance, assists with incident management, writes RCAs, and opens pull requests for fixes.
Let me show some of these using screen grabs.
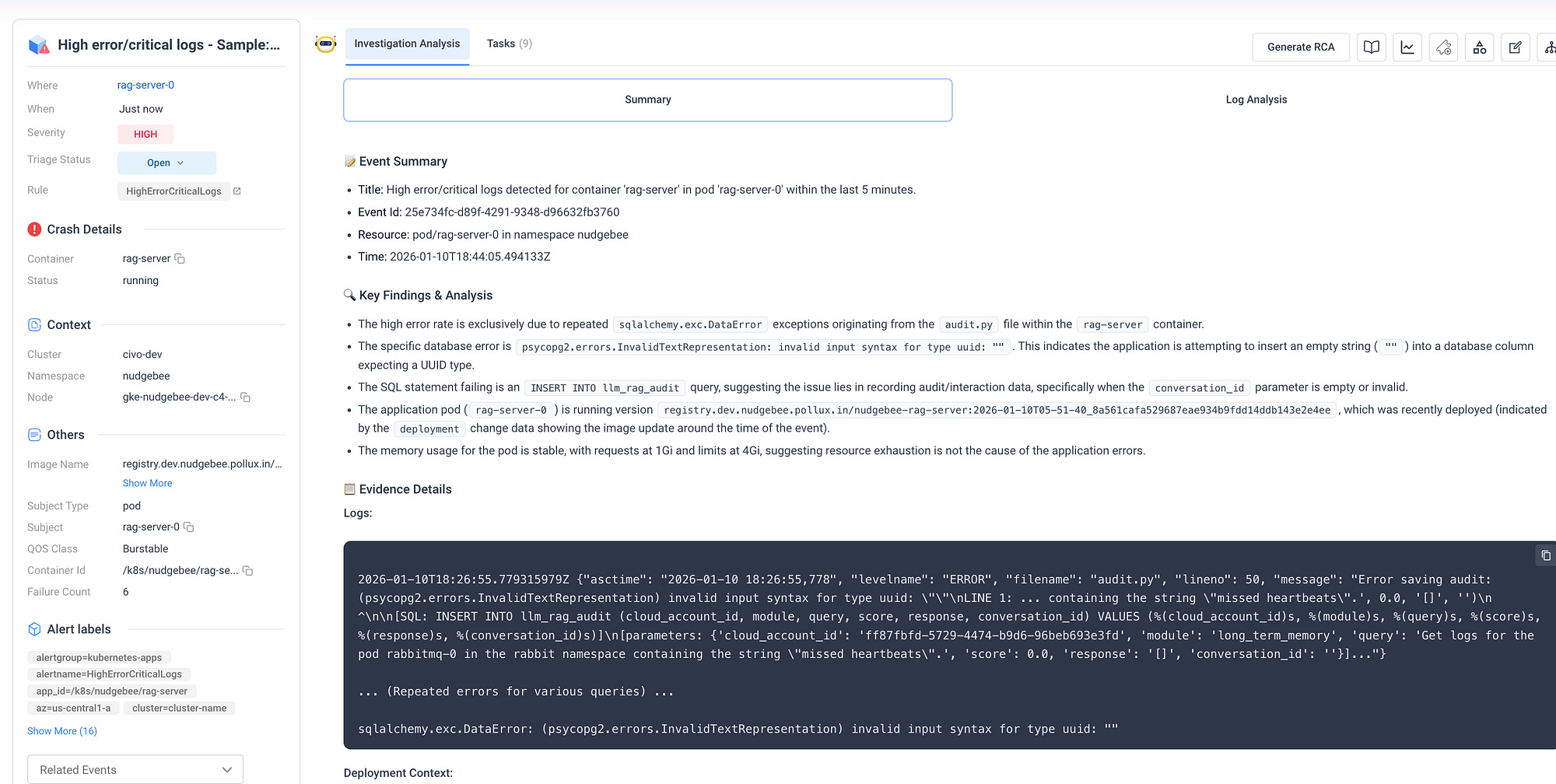
Incident management
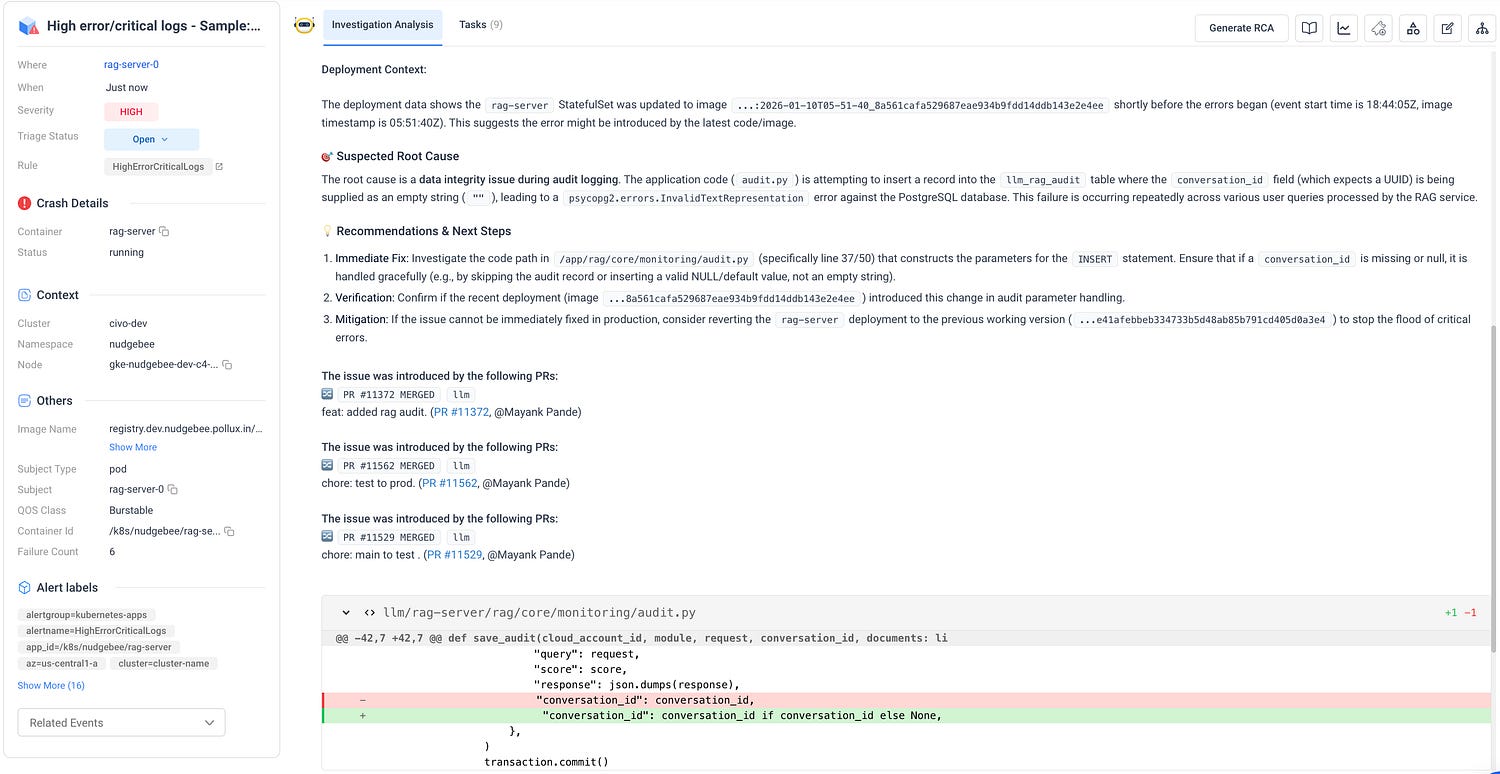
Instead of an engineer spending an hour digging through logs, Nudgebee surfaced the alert, analysed the deployment context, pinpointed the root cause, and recommended the exact fix in the same place.
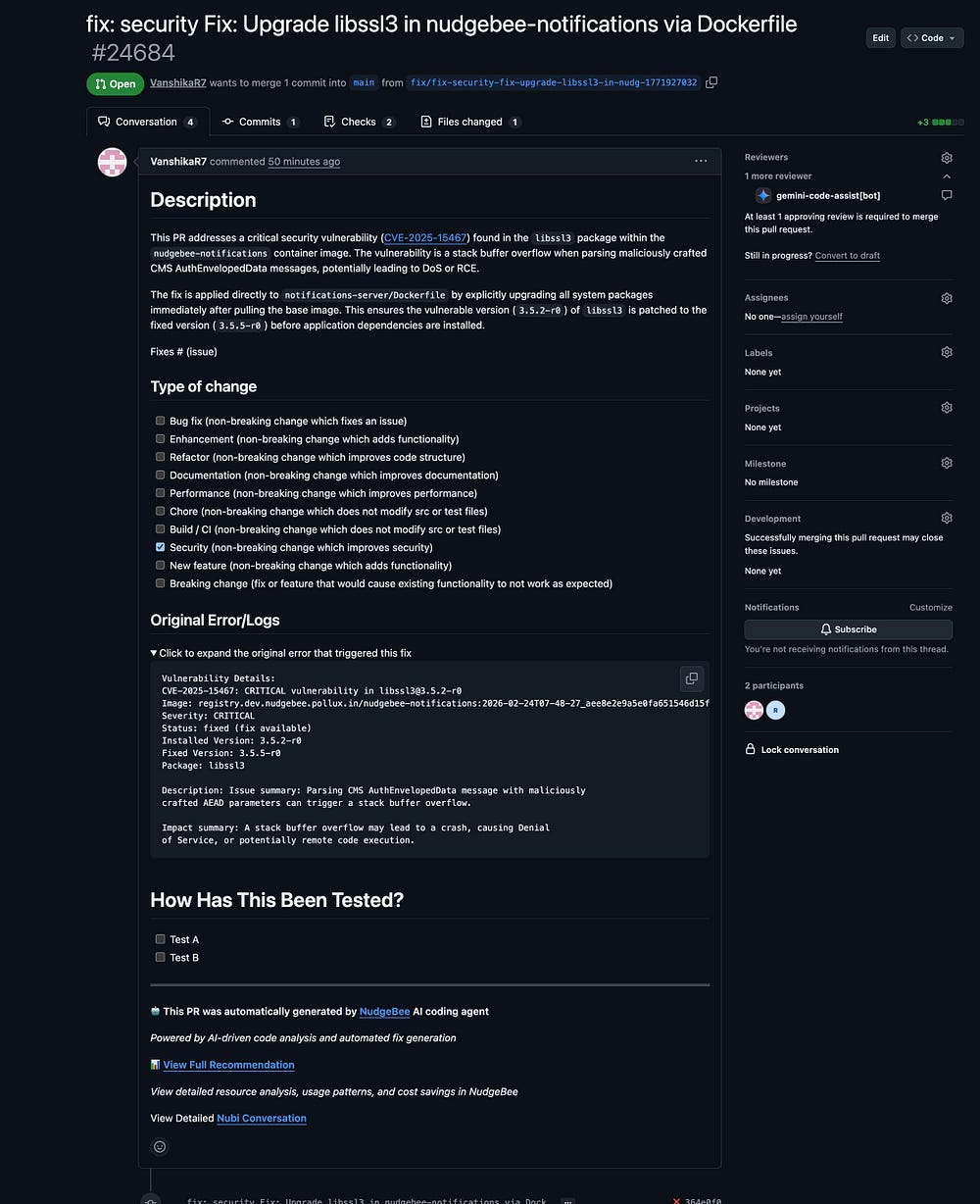
CVE fixes
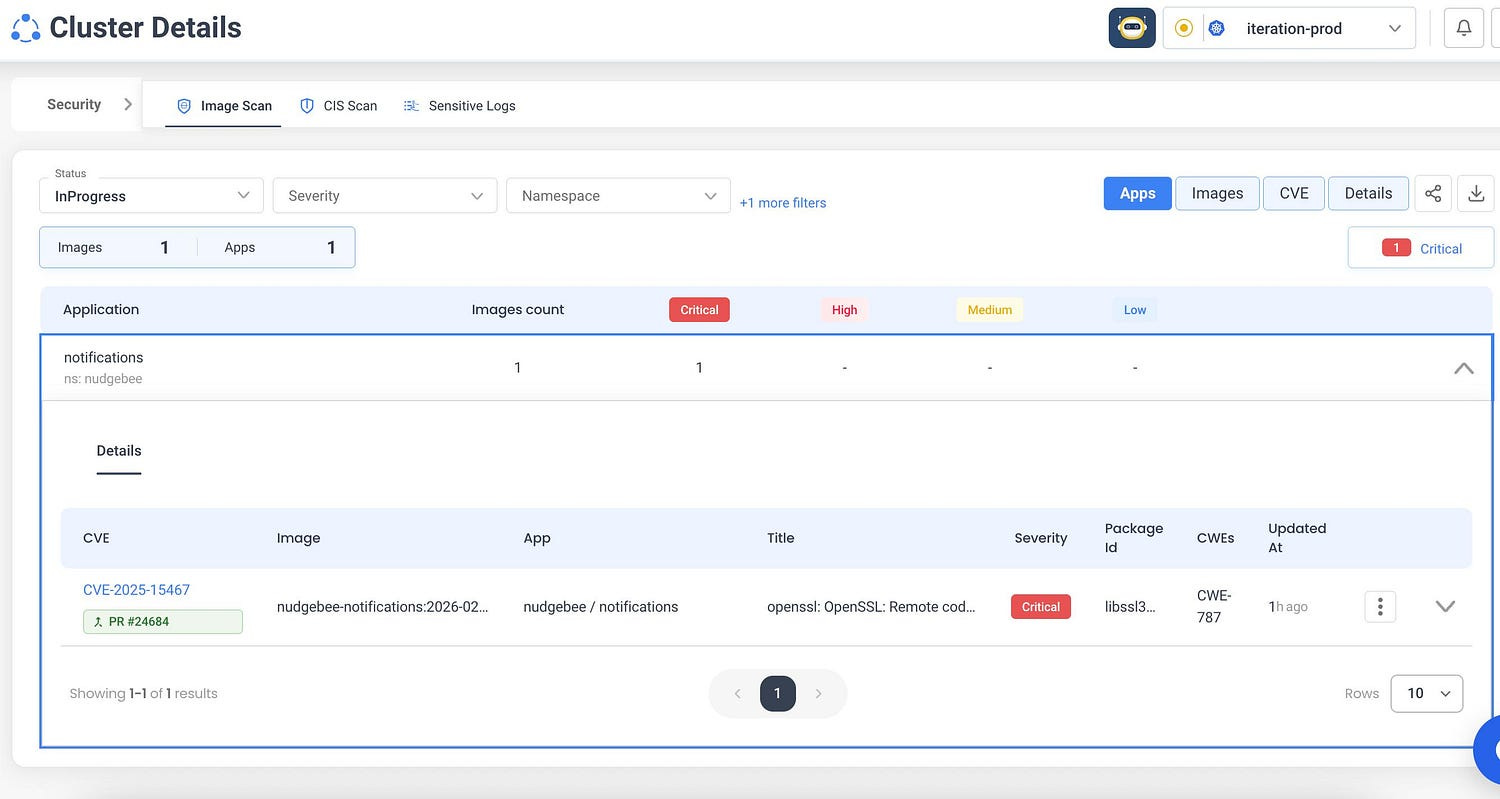
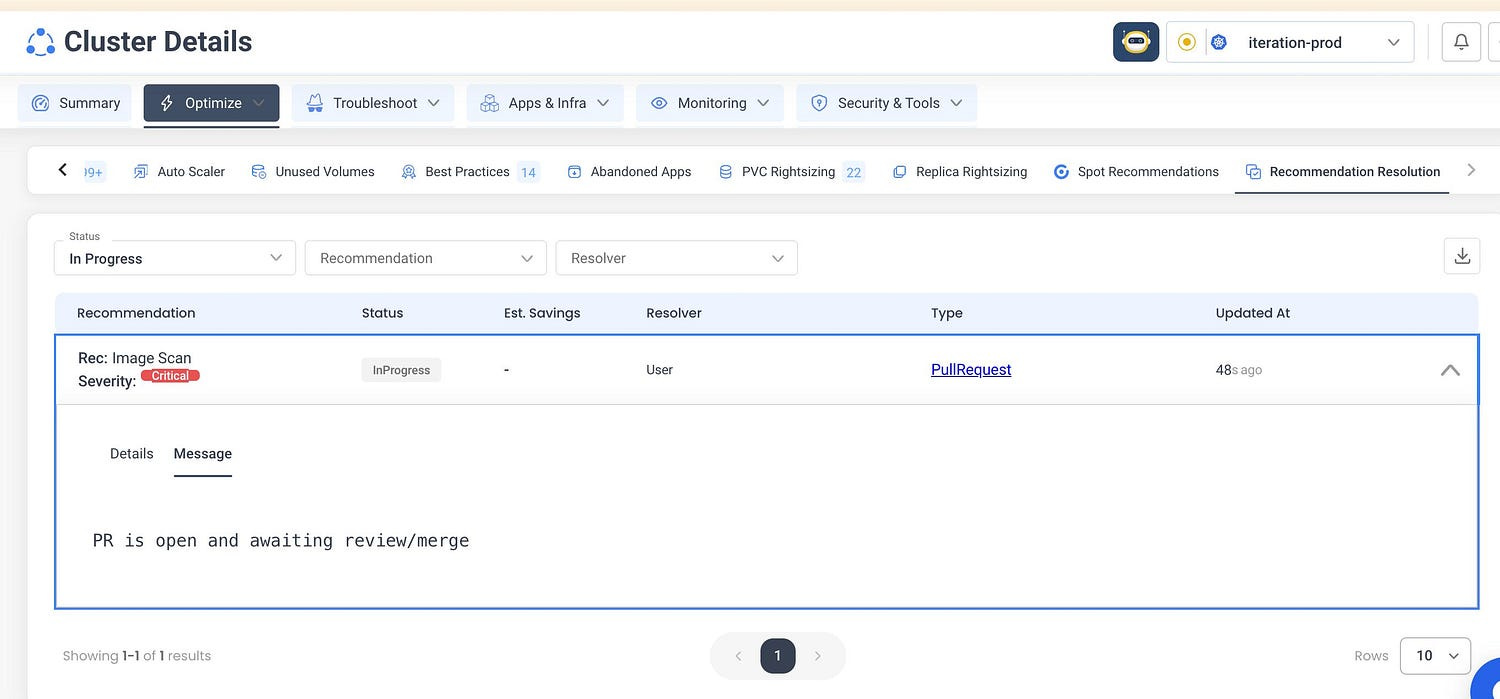
Nudgebee finds the vulnerabilities and automatically creates a PR to fix them.
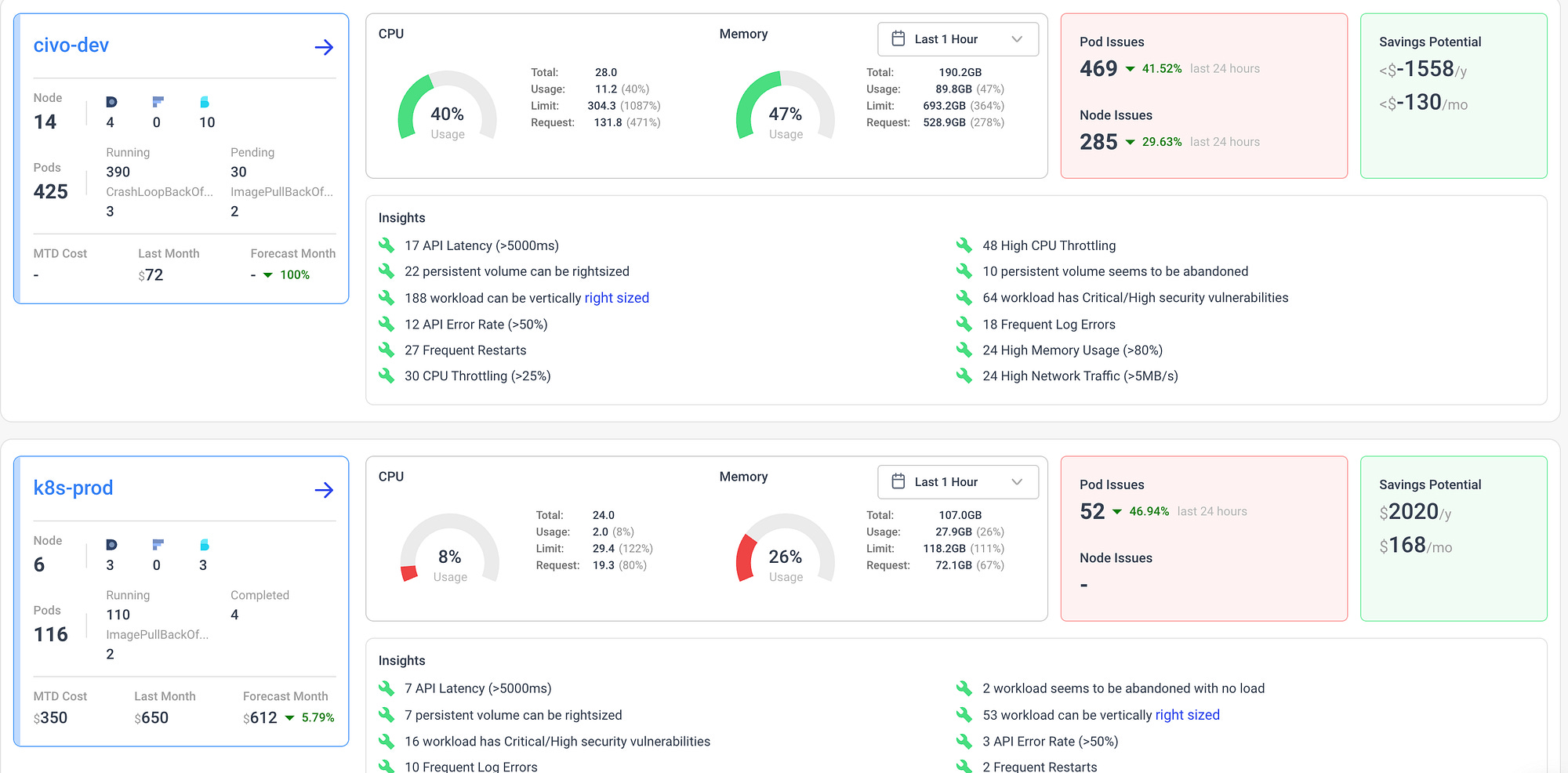
Cost-saving recommendations
Look at this. Two clusters, civo-dev and k8s-prod, and Nudgebee have already surfaced 469 pod issues and 285 node issues. It suggested $168 of monthly savings for the overprovisioned prod cluster.
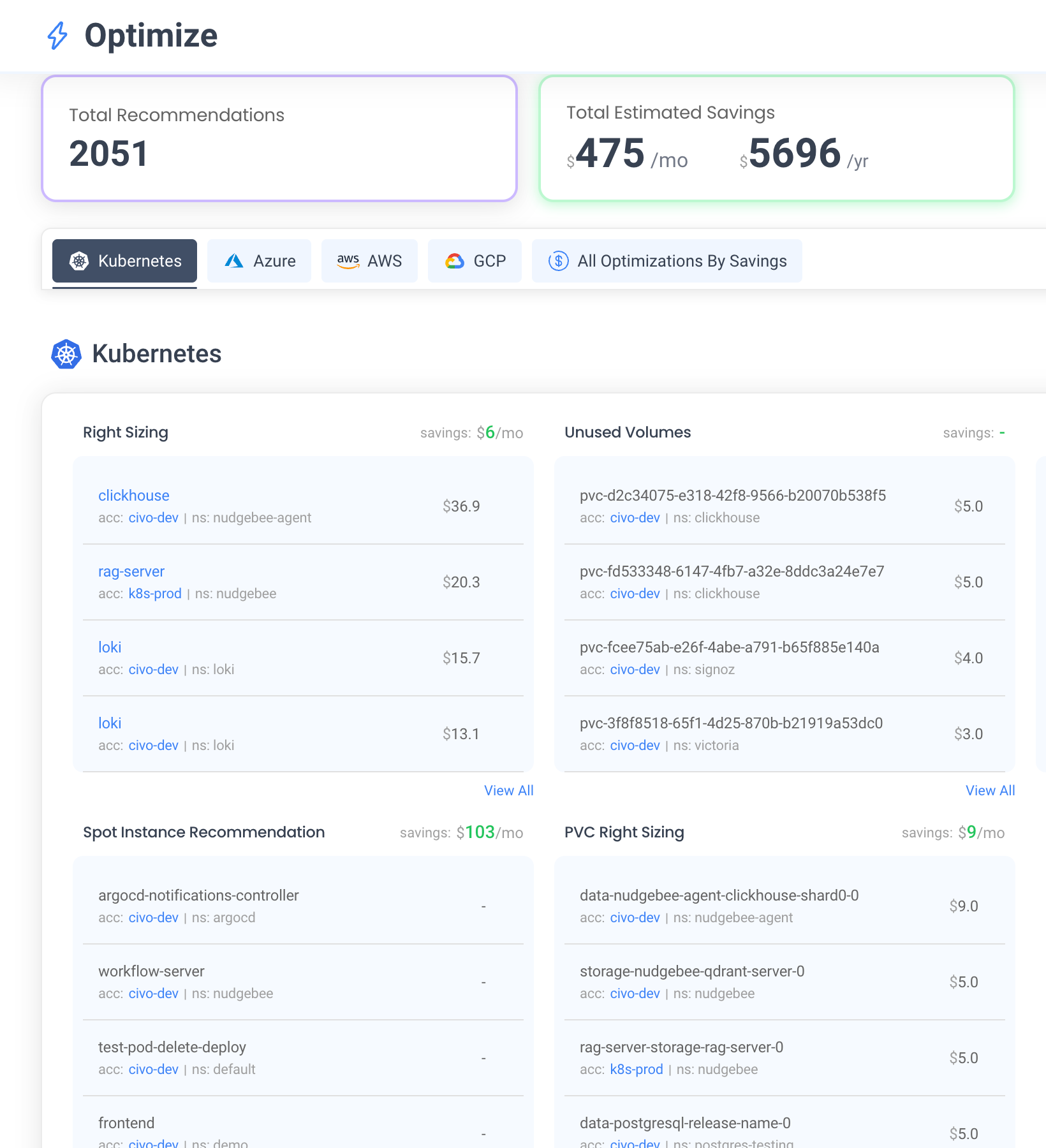
Right-sizing recommendations
It provides right-sizing recommendations for compute and PVC, identifies unused volumes, and suggests spot instance optimizations.
What Makes This Approach Actually Work
Most “AI for DevOps” tools give you more dashboards. More data. More things to look at. That is not the problem. You already have too many things to look at.
Nudgebee is built differently. It is agentic, meaning it does not just surface information; it takes action within guardrails you define.
It plugs into your existing stack. Prometheus, Datadog, Loki, Slack, Jira, PagerDuty, GitHub. No rip and replace. You are adding intelligence on top of what you already built.
And everything has an audit trail. Every action it takes, every recommendation it makes, every PR it opens. You stay in control. You just stop doing the work that should never have needed a human in the first place.
That is the version of DevOps worth building toward.
Want to see how Nudgebee works in your setup? Check out nudgebee.com